OCRのテストをしたいのですが、ネットになかなかちょうどいいテストデータが転がっていないのです。
著作権の問題が生じない・・・個人情報でもない・・・でもテストとして妥当と思えるような。
そこで自治体の申請書をダウンロードして手書きで適当な文字を記入してテスト用データを作ってテストすることにしました。
手順としては
自治体の申請書(3種類)を記入
↓
印刷
↓
FAXで送信
↓
FAX受信したデータをスキャン(PDF化)
↓
うちのOCRサービスで読ませる
という流れです。
手書きした書類をFAXで受信するといい感じに文字がかすれた状態になりました。



それではこの3データをうちのOCRで読み取らせてみます!
読み取るとExcelデータになります。
出てきた結果のファイルがこちら。まず1つ目。

2つ目がこちら。
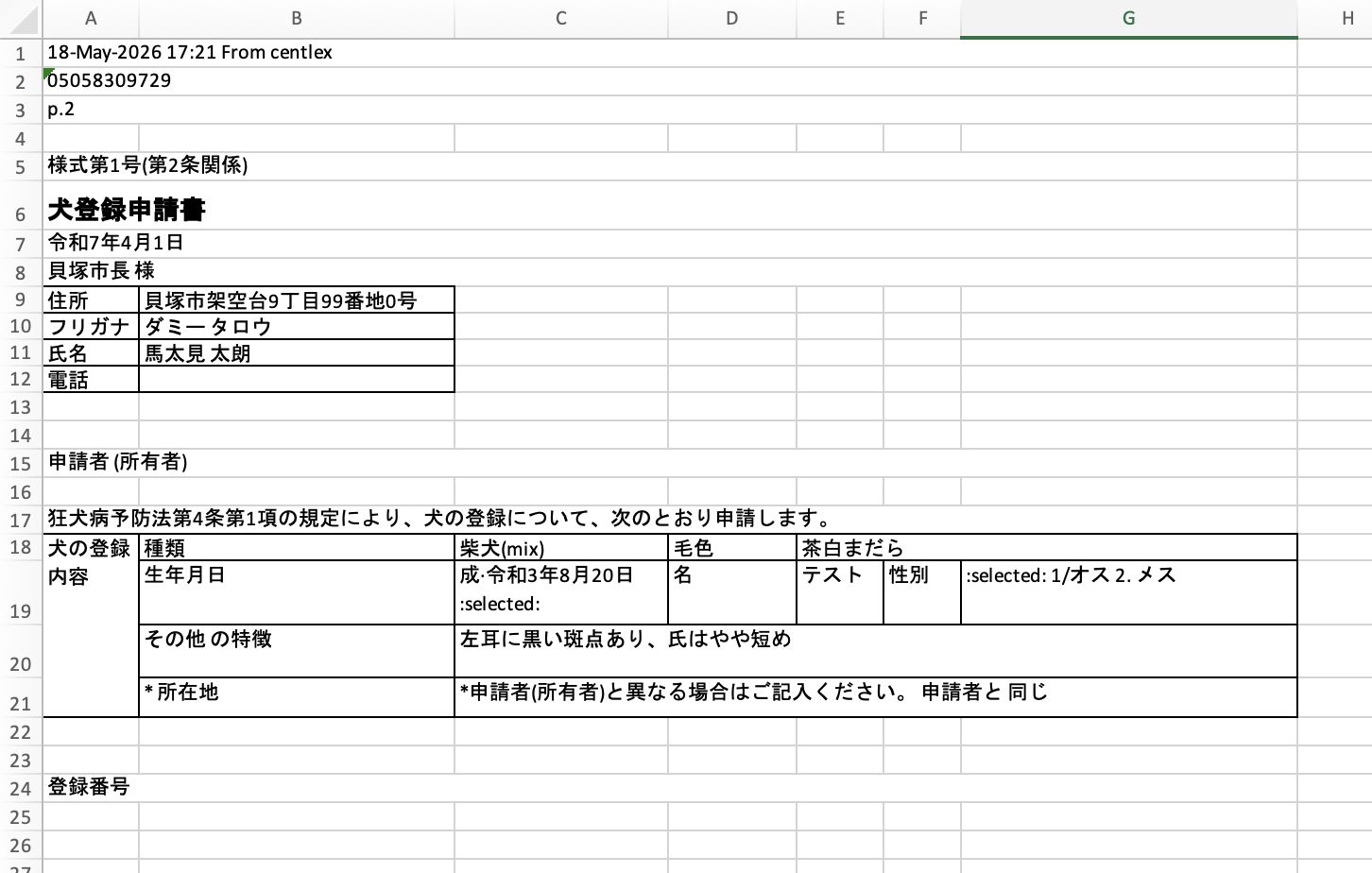
3つ目。

***** 1つ目の簡易専用水道給水開始届で誤認識した箇所 *****
①届出者住所
(記入)堺市仮名区架空通9丁目0番0号
↓
(OCR)世界市仮名区東交通9丁目0番0号
堺市を”世界市”と間違えるとは、、これはいただけないですね。
②簡易専用水道を設置した建築物の名
(記入)テストビル南棟
↓
(OCR)ラストビル南棟
“テ”を”ラ”と認識してしまいましたがここはそう見えても仕方ない気もするのでOK。
③同上建築物の所在地
(記入)590-0000 堺市中区架空町9丁目0番0号
↓
(OCR)7 49 0- 0007 堺市中区栄里町9丁目0番0号
“7 49″の7はおそらく”〒”を誤認識したと思われる。”590″が”49 0″と認識。数字は読み取ってほしいところですが、字の崩れ方、かすれ方を考えるとやむを得ないでしょうか。
④管理者の住所·氏名
(記入)〒 590 – 0000 大阪市架空区架空町9丁目0番0号 架空ビル管理(有)TEL.(072) 000-0002
↓
(OCR)T 500 – 000 大阪市辖区区架空町9丁目0番0号 职空ビル管理(有)TEL.(0774000-0002
“590”と書きましたが”9″がほぼ”0″に近くなってしまったので”9″と認識しました。
“架空”という文字が苦手みたいです。”2″と”)”が重なって”4″に見えなくないのでここはまあいいでしょう。
⑤延 床 面 積
(記入)3,280 m2
↓
(OCR)3.200 m2
“8”は字が崩れてはいるのですがここは察してほしいところ・・・。
カンマの字もはっきり跳ねているのでカンマとして認識してほしい。。
⑥容量
(記入)総容量14.4 有効容量12.0
↓
(OCR)総容量14.93 有効容量12.03
“4”が”9″に見えなくはない、ですが、もうひとつですね。立方メートルのm3の”3″を読み取っているのはいいでしょう。
申請書にもともと書かれている文字については何も書いていないテンプレートの状態を学習させるなどして不要に読み取らないようにできるか検討します。
⑦一日平均使用水量
(記入)約4.5m3
↓
(OCR)約94.5m 3
ここはなぜ4.5が94.5になったのか、ですがおそらく”約”という漢字のつくりの側を”9″と認識したのではないかと思います。”約”として認識しているのにその字の一部を再度認識してしまうのは良くないですね。。ここは調査して改善が必要です。
⑧水道使用者番号
(記入)TEST-2024-00001
↓
(OCR)TEST-2024-09001
00001を09001と認識していますがこれは申請書にもともとあった”)”と”0″が重なって”9″に見えるといえば見えるのでやむなし。このケースもテンプレートの学習で改善検討です。
⑨連絡先
(記入)072- 000-0003
↓
(OCR) 0772- 006-0003
ここも1つの文字を2回認識してしまう問題が発生しています。”000″を”006″と認識していますが、最後の”0″がつぶれており”6″と見えなくもないところでしょうか。
手書き文字はやはり精度が落ちますね!システムフォントの文字だったら99%は正しく認識するのですが。
前処理&後処理を工夫して、実用性を高めるという課題を見つけたのでそこにしっかり取り組んでいきます。
ほかの2種類はまた後日、検証します。